- Avicenna
- Posts
- Is This the Death of US AI?
Is This the Death of US AI?
Nofil Khan
June 08, 2025
Welcome back to the Avicenna AI newsletter.
Here’s the tea 🍵
Anthropic releases the long-awaited Claude 4 🤖
Anthropic revenue sky rocketing 🚀
DeepSeek is back 🃏
ByteDance joins the party 💃
The death of US AI? 🪦
Claude 4 released
For the last year, I’ve rambled on about how Claude is the best model on the planet. After the release of 3.7, I didn't think so. The model wasn't as good. There was definitely a magic to Claude 3.5 that Anthropic wasn't able to replicate in the subsequent models.
Now, over a year later, Anthropic has finally released Claude 4, both for Opus and Sonnet, and without a doubt, both models are absolutely phenomenal. Both are state-of-the-art, frontier-level models.
Most people can use Claude Sonnet 4 and will be fine. It will suffice for most use cases. I mean, over 10%+ better than OpenAI’s o3 is a ridiculous statistic I won’t lie.
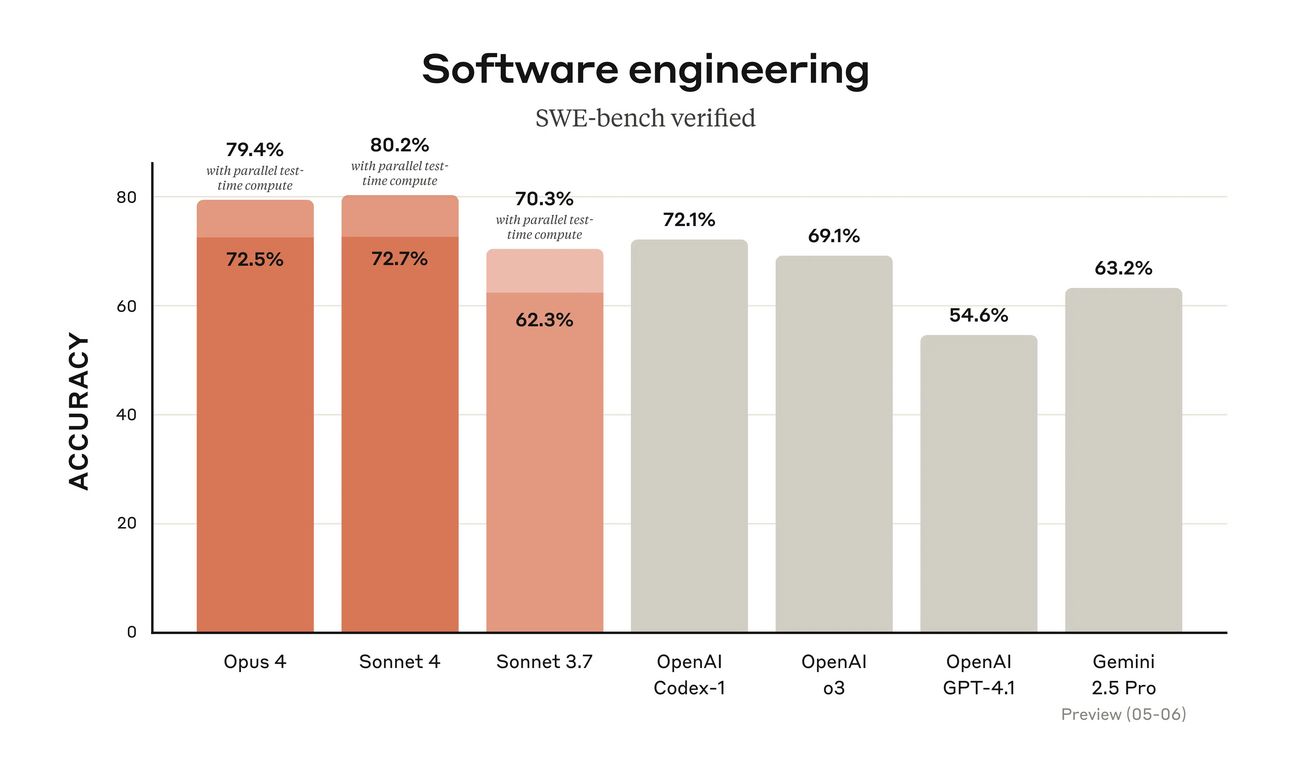
With reasoning on, I’d say Opus 4 is one of the best models on the planet. What makes Claude models stand out above other models is their agentic abilities. They can use tools and go back and forth between planning, reasoning and tool use in a way no other model can. This is what separates Claude from other AI models.
This is the reason why it’s the best model to use in Cursor. It’s the reason why GitHub is planning to integrate Claude Sonnet 4 into its Copilot agent.
What people don’t realise is that the models are already phenomenal. If we stopped developing better models right now, we would still spend the next 5 years finding workflows and ways to use models in current day jobs.
The reality is, to get best out of models, we need to give them access to tools just like a human. They need to be able to search the web, access docs and use external tools to achieve their goals. If a model can do this well, it will automatically be the best model to use for most applications and frameworks.
I’ve found both Sonnet and Opus 4 very good models. The models can still tend to go overboard and do more than what’s needed, but, I think that’s something we’ll have to live with. I’d recommend using them in Claude Code, Anthropic’s own coding terminal app, but, I feel like they churn through tokens unnecessarily. I use both models either directly on the website or through Cursor.
You can read more on Anthropic’s blog here [Link].
Just the beginning
Most people are already fatigued with AI. They heard it over and over again for months on the news and now it’s just another thing that’s out there. Most people aren’t particularly impressed by it and aren’t thinking about it too much.
Turns out AI adoption is only just starting. Businesses are slowly starting to figure out how much AI can do for them. After two and a half years and many landscape shifts, AI adoption is starting to scale.
At the end of March, Anthropic’s revenue was $2 Billion.
Two months later and it’s $3 Billion [Link].
In what other time has a company been able to add a billion in revenue in two months?
Unprecedented times we’re living where a handful companies will scale in ways we’ve never seen. NVIDIA was the catalyst.
Anthropic has also slowly been expanding Claude’s capabilties. Claude can now:
Access gmail, calendar and drive to analyse docs. Can’t make edits yet.
Can search the web. I’ll be honest, they’re web search is shit. OpenAI’s is significantly better with o3.
They recently released their research function to Pro users. It can create reports and go through hundreds of sources; I’ve yet to compare it with OpenAI and Google’s Deep Research though.
You can also connect Claude to eternal tools by building your own MCP server. This is actually pretty cool, would you want me to show you how to set this up?
DeepSeek is back
Yes, DeepSeek is finally back.
Months after they shocked the world with a frontier open source model, DeepSeek has NOT released a successor. Instead, they simply updated the original R1 model they released.
The result?
Same as last time. A frontier level open source model.
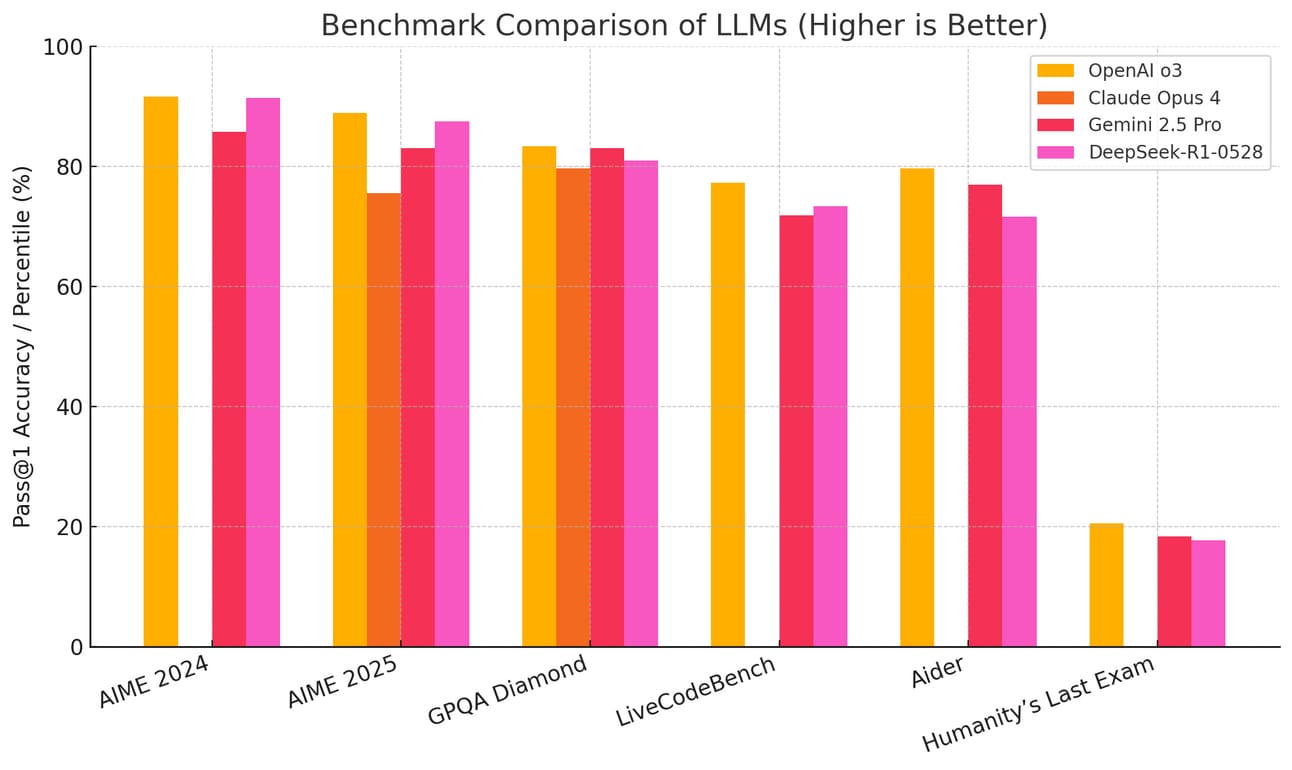
DeepSeek is basically on par with the best frontier models.
The new model called R1-0528, great naming I know, is essentially as good as the best models on the planet. All of these models are frontier models:
Claude Opus & Sonet 4
OpenAI o3 & o4
Gemini 2.5 Pro
DeepSeek R1-0528
Although a new update to Gemini gave it the same sycophancy bug ChatGPT had a few weeks ago [Link].
On the LiveCodeBench test, it ranks 4th behind only o3 and o4, two of which are high compute variants.
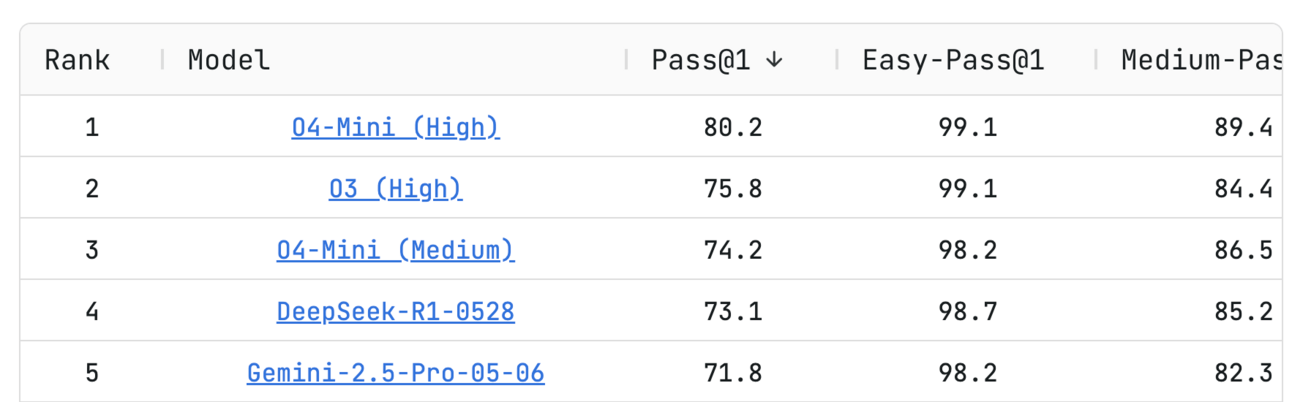
Once again, this is so good for open source AI. Here’s hoping Meta and Mistral can contribute to open source AI in a similar fashion. OpenAI also said they’d open source a frontier level model, but I won’t hold my breath for that one [Link].
You can access R1’s weights on HuggingFace [Link].
There is a problem with this model as well as other open source models we need to talk about.
Tool use.
Open source models are terrible at using tools. This is a rather big problem if you want to build agents that can work autonomously. Most platforms that support open source models don’t support tool use; meaning you’d have to set this up yourself. Most people won’t be doing this.
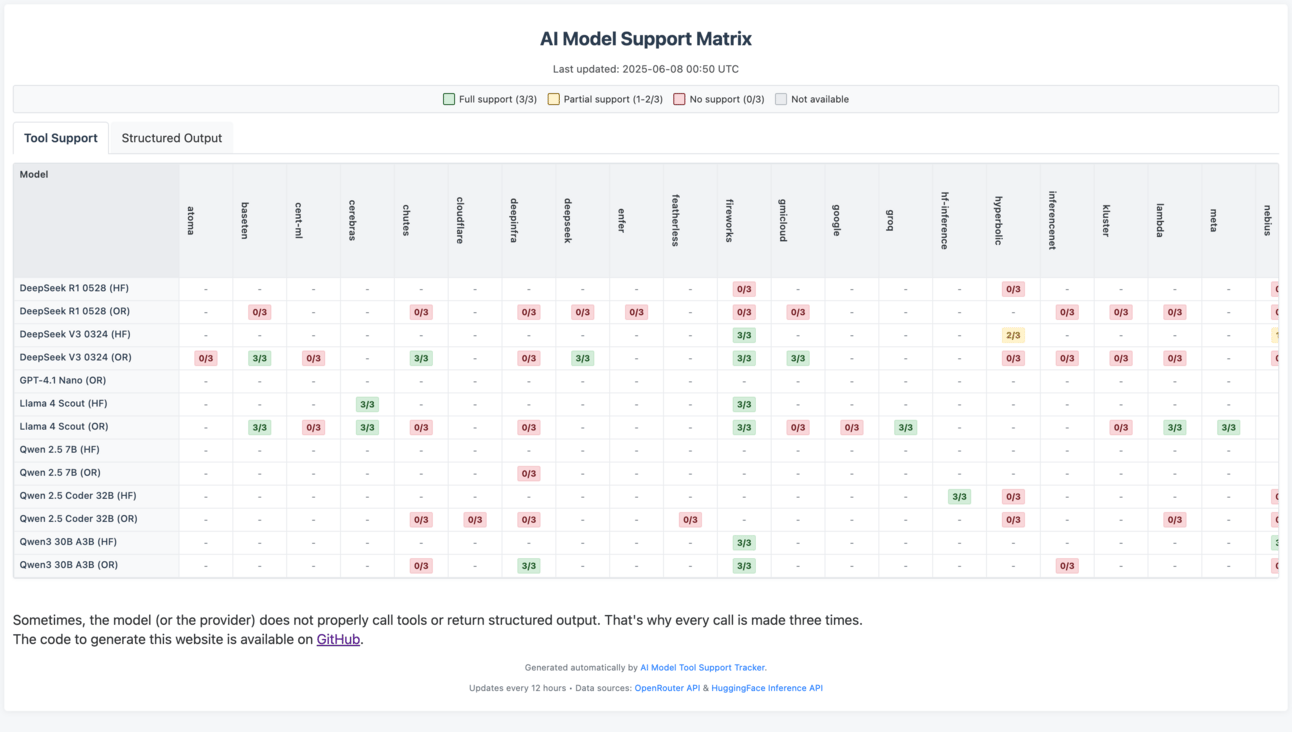
This website is a very handy website to see which platforms support which models and also tool use. You’ll notice the support is very limited. This is an open source project so you can check out the code and contribute here.
What makes Claude great, besides its inherent abilities, is its ability to call five, ten, 20+ tools in one go, getting data from different sources, searching the web, synthesising ideas etc. Once open source models can do this, it will be a lot cheaper to create agents with long running tasks.
I think OpenRouter is best positioned to solve this problem, but I don’t think it will happen soon unfortunately.
ByteDance unveils Seed-Coder
DeepSeek isn’t the only frontier level AI lab from China. I’d put Bytedance Seed in the same category. They’ve been releasing some very high quality papers recently. For example:
Seed-Coder: A new way to create data for models. Instead of collating data manually, they’ve created a “model-centric” approach by using different LLMs to create training data. What’s fascinating here is that they’re essentially creating a way for the model to understand what constitutes good training data, and specifically train coding AI models.
Seed 1.5 VL: A new vision-language multimodal model with 20B parameters that excels at GUI control, gameplay, and visual reasoning tasks. Achieves state-of-the-art performance on 38 out of 60 public benchmarks, trained on 3 trillion tokens. What's impressive is its practical agent capabilities - it can actually control interfaces and solve visual puzzles, not just describe images.
BAGEL: An open-source unified multimodal model, meaning a single model that can handle different modalities (text, generating images, editing images). It rivals GPT-4o on some benchmarks. It can also learn navigation and editing skills from video data, making it surprisingly capable at complex visual tasks.
These are just some of the things Bytedance Seed is working on, and apparently they will be releasing a video model to rival Google’s Veo 3 soon. I’m not sure I believe this, but, it doesn’t have to be true.
At some point, next week or next month or even next year, I would expect Bytedance Seed to release one of the, if not the best AI video model on the planet. Considering they have all of TikTok to work with, they have no shortage of video training data.
Speaking of Veo 3, there’s now a fast version that consumes 20 credits instead of 100, and gives a 8s 720p clip in ~1m20s [Link]. There are already pages on TikTok with millions of views with just Veo 3 clips.
What will happen when Bytedance integrate AI video gen natively into TikTok?
The amount of AI video slop on social media will be unimaginable. I don’t see how this will play out in a positive manner. Only one way to find out I guess.
The death of US AI?
Have you noticed that the recent release of the new R1 model didn’t make international headlines?
It’s a Chinese model that is open source and is on par with US AI models. Yet, for some reason, we aren’t clamouring at the dangers of Chinese AI. Most people don’t even know it’s been released…
This is why I don’t take the AI safety folks too serious. There are definitely dangers; just not the ones people are talking about.
You might be wondering though, is this what I was referring to in the title?
Is DeepSeek and Bytedance Seed going to kill US AI?
No, of course not. Open source AI and research is good for everyone, including the US.
The death of US AI will come with the culling of talent. One of the reasons US AI labs are better than everyone else is because they have the best talent in the world. The smartest and brightest engineers and researchers take their talents to the US to work on the hardest problems and reap the rewards. For the longest time, the US has been the go-to place for such people. No longer.
The Trump administration’s latest move to tighten restrictions on foreign student visas, particularly students from China, is not a good thing for these labs. At the time of writing this newsletter, the administration has told embassies to halt all international student visa interviews [Link]. It’s currently unclear how closely this is being followed.
Perhaps it’s not apparent, but a very large number of researchers and PhD holders are foreign students. For example, last year at the University of Chicago, foreign students accounted for 57% of Computer Science PhD enrolments [Link].
This is literally a death sentence to STEM and AI labs in the US. It’s not like it’s a simple subtraction for the US in terms of talent either. Every person leaving is another person joining somewhere else.
CEO of NVIDIA Jensen Huang recently pointed out that ~50% of the entire worlds AI researches are Chinese, and warned that the US is risking its reputation as an AI leader by failing to protect and develop that talent. Instead of doubling down on education and up-skilling the next generation of AI workers, the US is actively pushing them away.
It’s not just immigration either. Funding cuts to research aren’t doing the US any favours.
Take the example of Ardem Patapoutian.
Ardem is a Lebanese immigrant. He spent a year writing for a newsletter and delivering pizzas so he could be eligible for Uni. He went on to get his undergrad and post fellowship in neuroscience. He won a Nobel Prize in 2021.
Recently, his lab’s funding was frozen. In a matter of hours, he received an email from China offering to move his lab to “any city, any university” and promised to fund him for the next 20 years. Ardem declined the offer.
But how many new researchers are going to reconsider going to the US?
A younger version of Ardem may not even get a visa if he tried today.
I’m not trying to say what the US should do when it comes to immigration or how they should manage their spending. But, it’s painfully obvious that what they’re doing now will only hurt their position in the AI arms race. Universities and countries are already trying their best to now nurture home grown talent so they won’t leave. Leaders from top labs like Google have already left to join AI labs in China.
I’m not saying it’s over; but this is what the first steps would look like.
You can read about Ardem’s story here [Link].
I want to keep bringing these AI updates to you, so if you’re enjoying them, it’d mean a lot to me if you became a premium subscriber.
As always, Thanks for Reading ❤️
Written by a human named Nofil
Reply