- Avicenna
- Posts
- The Google Behemoth is Accelerating
The Google Behemoth is Accelerating
Nofil Khan
June 01, 2025
Welcome back to the Avicenna AI newsletter.
Here’s the tea 🍵
All the updates from Google’s I/O 🤖
Chatbots for mental health therapy 🧠

Avicenna is my AI consultancy. I’ve been helping companies implement AI, doing things like reducing processes from 10+mins to <10 seconds. I helped Claimo generate $40M+ by 10x’ing their team efficiency.
Enquire on the website or simply reply to this email.
p.s the timeline page on the website is now working! Every single AI related news in one place. Working to back date all the data + make it real time. Stay tuned.
Google proves they’re king
Just over a week ago, Google held I/O, a yearly developer conference where they announce and launch new tech. This years event was perhaps the most insane one yet.
Veo 3
Veo 3 is, without a doubt, the best AI video generation model on the planet. This is the first time a video gen model has been released that can create videos that are actually indistinguishable from reality. Millions of people can very easily be fooled with an AI video generated using Veo.
We now have hyper realistic image, video, and audio generations. Nothing on the internet can be trusted anymore.
What makes Veo 3 even more impressive – and rather scary – is that it has inbuilt audio generation which is nigh perfect. It’s crazy how good it is. It can also adhere to prompts very well, like whispering, singing, holding things, or saying certain things. Just look at some of these examples:

A close up video of a twitch streamer in a low lit room, in an ASMR style [Link]
No joke, some of the videos actually scare me.
Over a year ago, I wrote about the future of human x AI interaction and reflected on the endless media one could potentially consume thanks to AI video generations. This is our first glimpse towards that reality. Is this the best video generation will ever be?
No, it’s the worst it’ll ever be.
Is Google the only company with this level of model?
Also no; many more models will be released and some will be open-source.
The reality is, we are creating the ultimate entertainment engine – one that is limited by virtually nothing. Nothing is too crazy, no scenario too wild, no world too vibrant; anything will be possible to generate.
Take a guess: what do you think people will generate?
…
One of the reasons Veo is so good is because Google has access to billions of videos on YouTube. They also happen to have some of the best AI talent on the planet.
Currently, Veo 3 has just two drawbacks:
It’s very expensive
Video outputs are limited to 8 seconds
You can only use Veo in the Gemini Pro or Ultra sub. Gemini Pro only gives 1,000 credits. You’ll burn through these in a few videos max.
Ultra, on the other hand, gives 12,500 credits. You can also buy extra credit packs if you run out, which you will.
The Ultra sub is $250USD/month…
While I’m not sure the pricing will change any time soon (good AI is expensive), I’m sure future releases of Veo will show increased output capacity so creators can generate longer and more detailed videos. Considering Google’s already signed a contract to have Veo used in movies, I wouldn’t be surprised [Link]
Read more about Veo 3 here [Link].
Gemma 3n
Google also announced Gemma 3n, a mobile-first AI model that is probably the future of AI use. The model is only 4B params and is somehow comparable to frontier models like GPT-4.1 and Claude 3.7
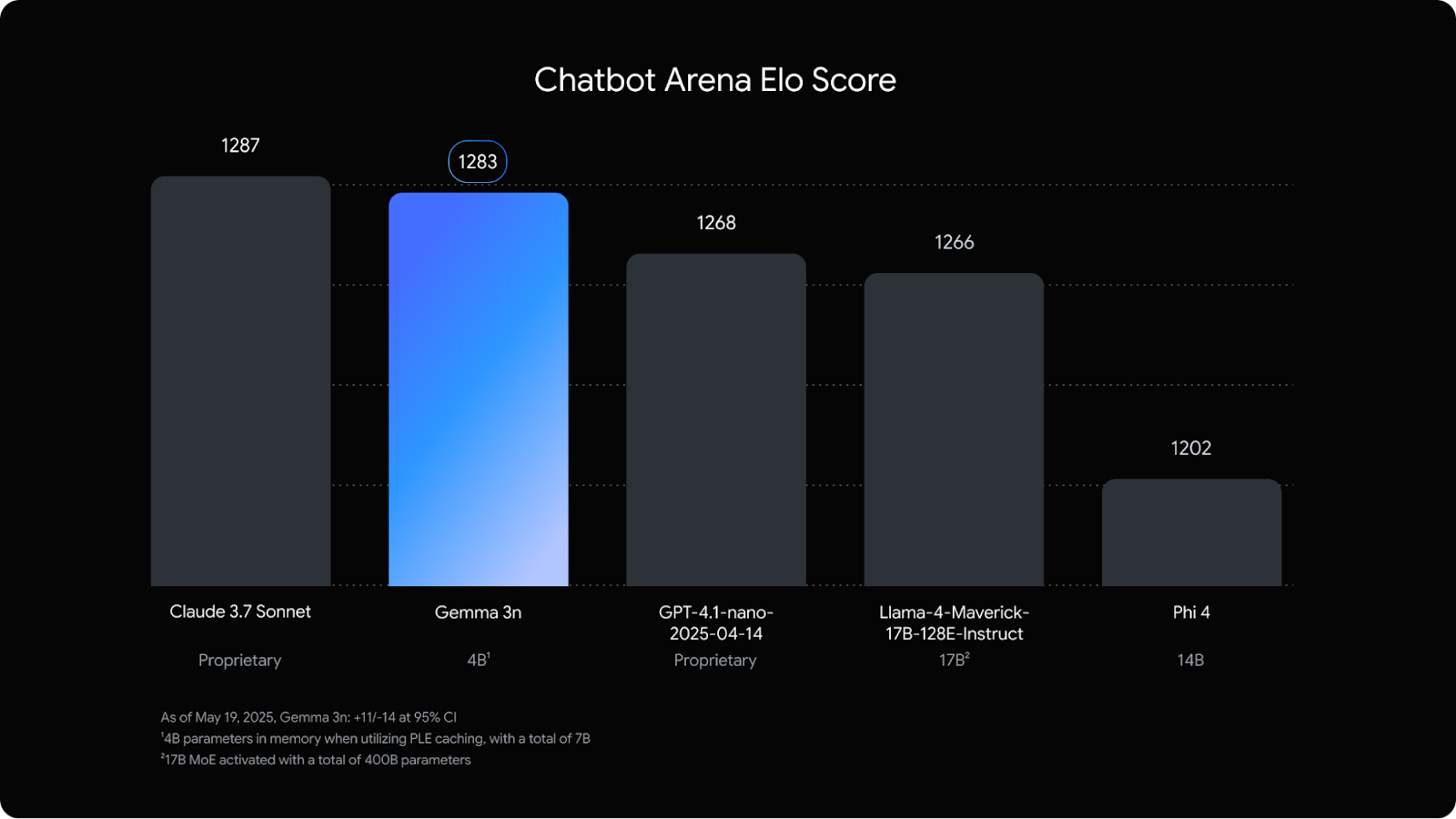
It’s 15x faster than its predecessor and can process multimodal inputs like audio, video, and images. Plus, it doesn’t rely on cloud connectivity, which means you can use it offline which is actually pretty cool considering it won’t really matter what phone you have since the model will only need 2GB of RAM to work.
I actually think its phenomenal that Google is not only building some of the biggest and best AI models, they’re also building the future of AI on phones, which will be used by millions around the world.
It’s all well and cool, but, I won’t pretend there aren’t any privacy concerns.
Regardless, this is a crazy step in the right direction for AI on mobile. Mind you, it may not necessarily be on mobile; if such a small model can be that good, imagine it in a small robot, glasses or headphones. The possibilities are almost endless.
You can actually try this model right now in AI Studio under the Gemma models [Link].
Jules
Google also announced Jules, a coding agent that integrates with GitHub and can do things like writing tests, building new features, fixing bugs, and creating and completing pull requests. Because it operates asynchronously, you can keep it running in the background while you work on other tasks, and it’ll then prompt you when it’s done and let you know what it’s actioned and any changes it’s made.
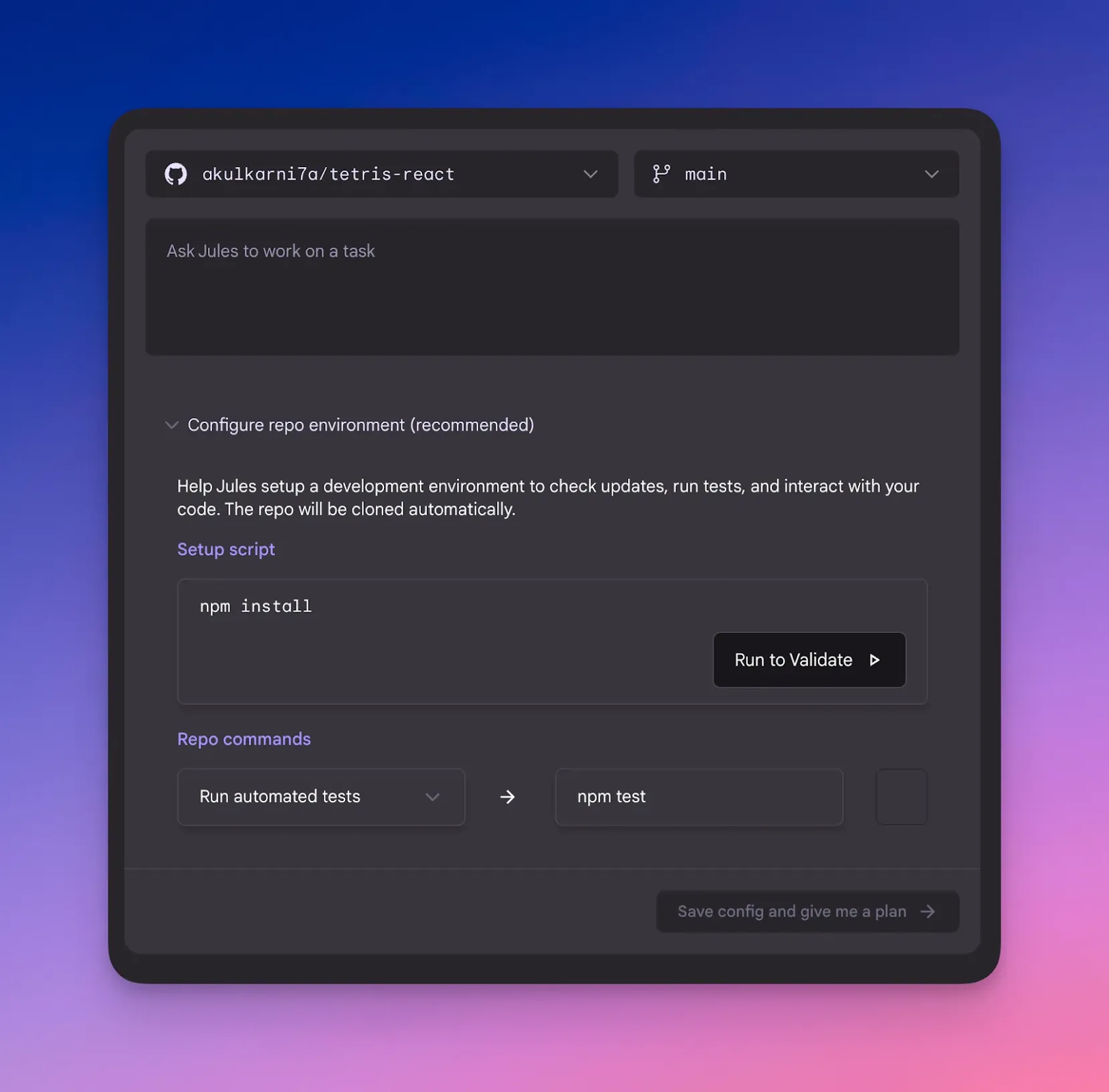
What’s really cool about Jules is that it clones your codebase into a secure Google virtual machine (VM), so it’s secure. Google won’t use your code to train their models while your code is living in an isolated location.
Jules is currently in public beta, which means anyone can access it and see how it stacks up against other coding agents (hint: it’s pretty good).
Try Jules now [Link].
Stitch
Another all-new release at the I/O conference was Stitch, a Google Labs experiment that lets users create UI for mobile and web apps using plain language. It’s been designed to bridge the gap between designs and functional sites or apps, which traditionally has been a source of much pain and back-and-forth between designers and developers.
While this one is still pretty rough around the edges – it is in its infancy, after all – it’s a huge sign of what’s to come and how AI could continue to simplify tasks across a tonne of different industries.
Stitch actually used to be Galileo AI, a company I wrote about well over a year ago.
I think right now, the best way to use Stitch is to iterate over designs and then provide that to a coding agent to build. You can also export the design to Figma but this isn’t something I’ve tested.
You can try Stitch here [Link].
AI Edge Gallery
Google also recently launched Google AI Edge Gallery, an official open-source app for running an AI model locally on a phone. Don’t ask me why its called edge gallery, I have absolutely no idea.
Here are the benefits:
It’s completely free.
It works offline, meaning you can use it wherever you are and at any time.
It’s multimodal, so can understand and process inputs other than text, such as photos, videos, and audio.
This works extremely well with the new Gemma 3n open-source models that I just spoke about.
With AI Edge Gallery, everything happens on your phone, which currently, must be an Android (although the iOS version is coming soon). Start by going to the ‘Releases’ section, then download and install the .apk file.
The app is then split out into three sections: Ask Image, Prompt Lab, and AI Chat. You can click on one to download a template, or import your own models. Once downloaded, everything can happen 100% locally on your phone with no need for cloud or internet connectivity to analyse images or chat with the AI model.
Google has released a bunch of model scenarios to show what AI Edge Gallery is able to do, and they’re impressive. Take a look at these:
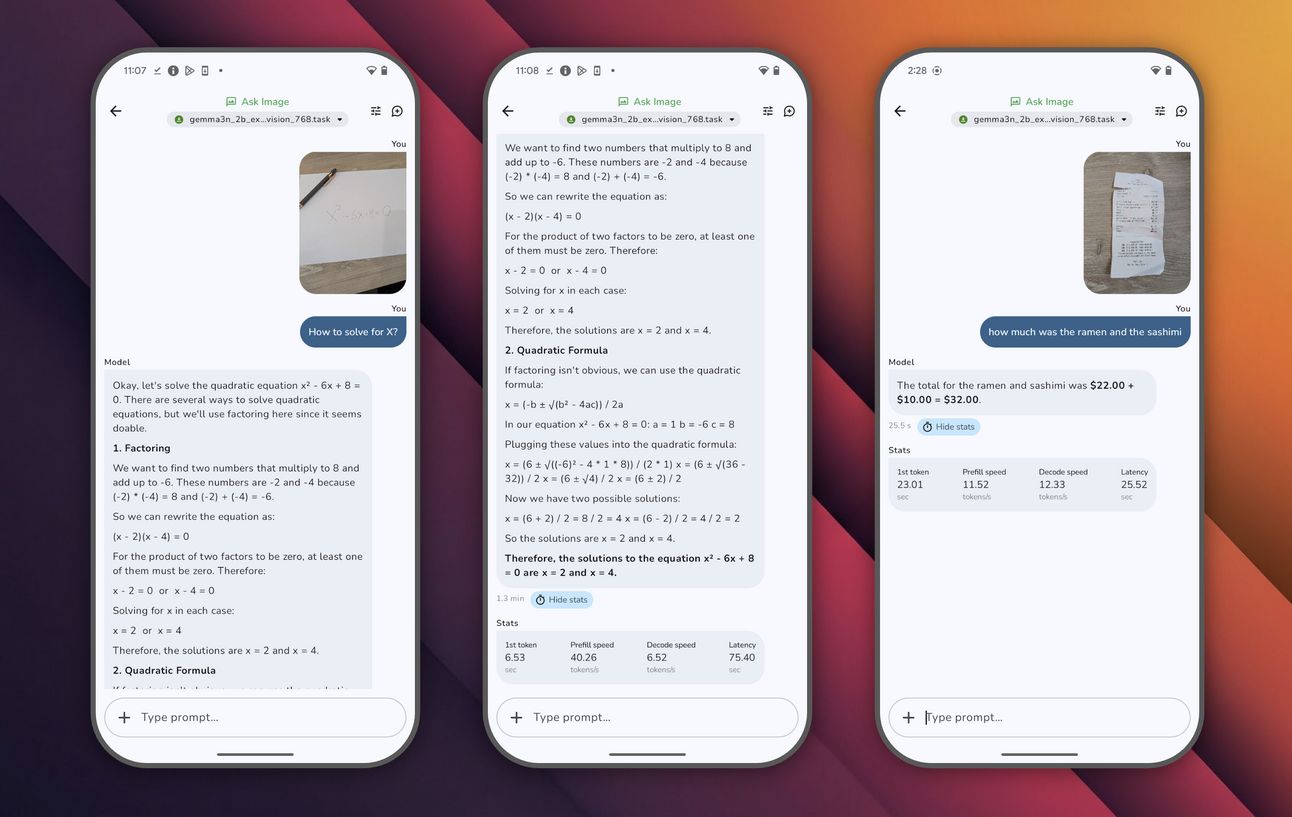
AI Edge Gallery’s Ask Image function.
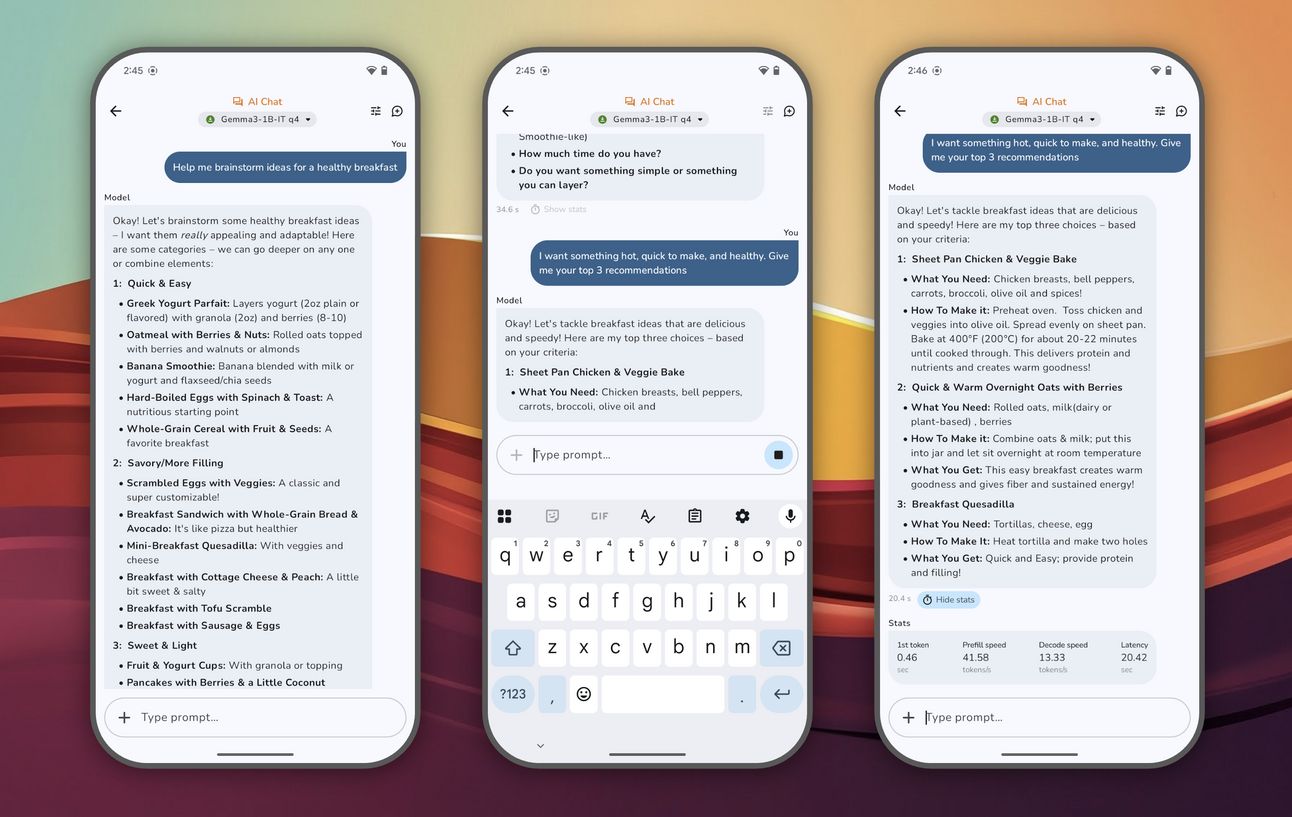
AI Edge Gallery’s AI Chat function.
Gemini Diffusion
The last update I want to really highlight from I/O is Gemini Diffusion, an experimental AI model developed by DeepMind that takes a new approach to text generation using the diffusion techniques traditionally used in image gen.
This means it can generate content a massive 5 times faster than it’s previously been able to – I’m talking building an entire, albeit simple, app in mere seconds. It’s so close to being instant that it’s almost scary.
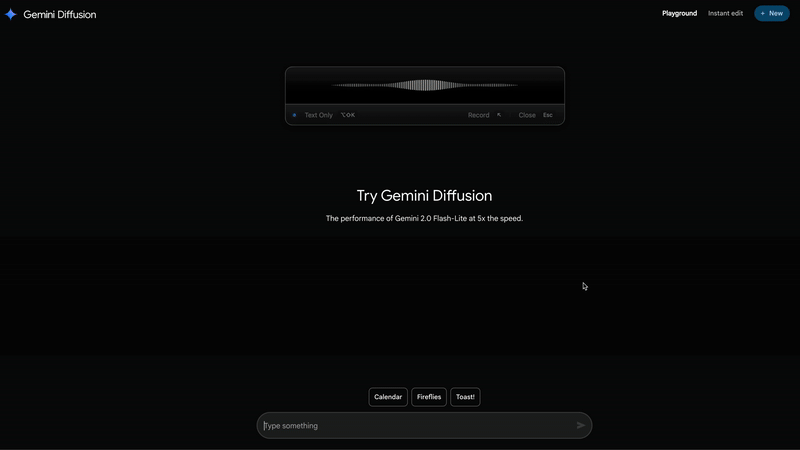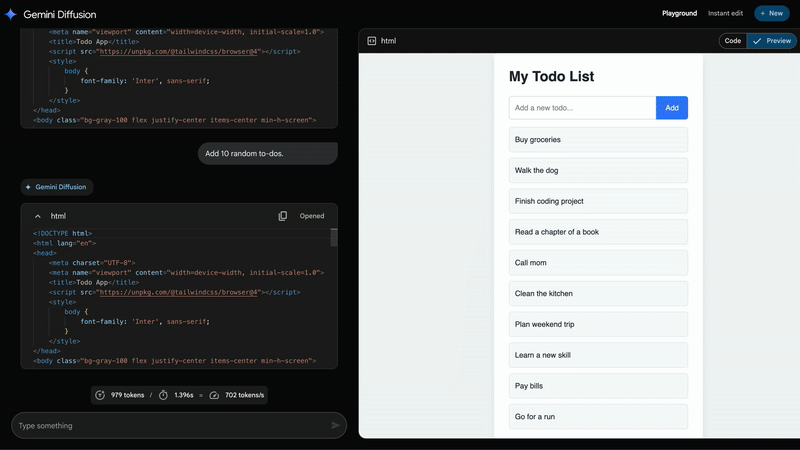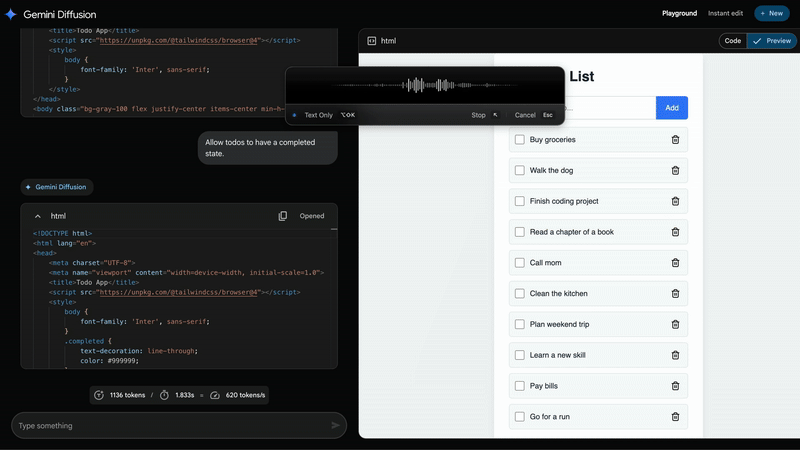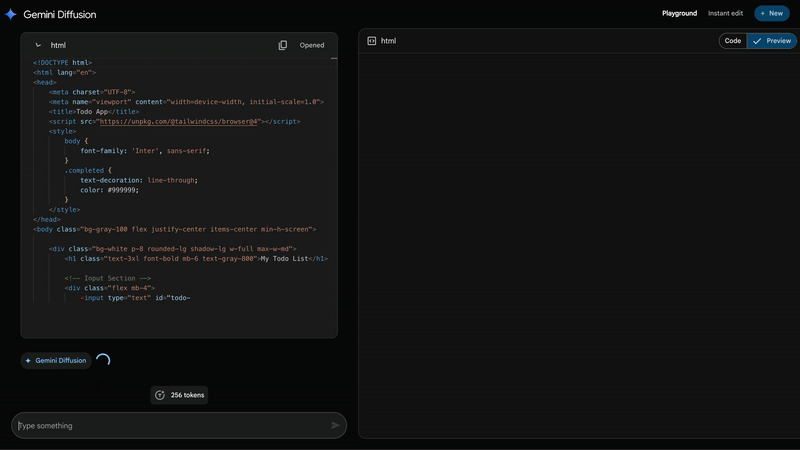
Just look at how fast it writes code. Imagine a thousand of these running simultaneously, writing, testing and deploying code. Mind you, code is just the tip of the iceberg. Most people are barely scratching the surface for what they can actually do with LLMs. Perhaps I’ll write about this someday.
Other major updates from the I/O conference:
The new Lyria RealTime AI music generation model, which currently powers MusicFX DJ, now available more broadly via an API. They’re taking a more collaborative approach with this, calling out the copyrighting issues that have begun to plague the music industry since the introduction of AI [Link]. Google’s generative media platform is coming together, as I wrote about many months ago.
Real-time Speech Translation for Google Meet video calls. This is still in beta, but it’s giving us a taste of what the future of communication could look like. When turned on, Speech Translation will automatically translate the speaker’s voice into the chosen language in real time [Link].
Project Mariner, an AI agent that can autonomously do things on the web [Link]. Who better to build such a tool than the company that literally runs the internet?
Project Astra, another DeepMind prototype for a universal AI assistant with fully multimodal capabilities, designed to be proactive, intuitive, and work across devices like smartphones and smart glasses [Link].
Firebase Studio now lets you import designs from Figma and create mobile prototypes also [Link]. If Google figures this one out, it’ll make building apps easier than ever before.
Where Google fits in the current state of play
If Google continues to ship at this rate, there won’t be a single pie they won’t have their fingers in. You know the funniest thing?
Following this insane I/O, Google stock price actually went down…
It also comes as stats are showing that Google AI usage has shot up like crazy. Way more people are using AI in general now, and with the fact that Google lets you use the best models for free, I’m not really surprised.
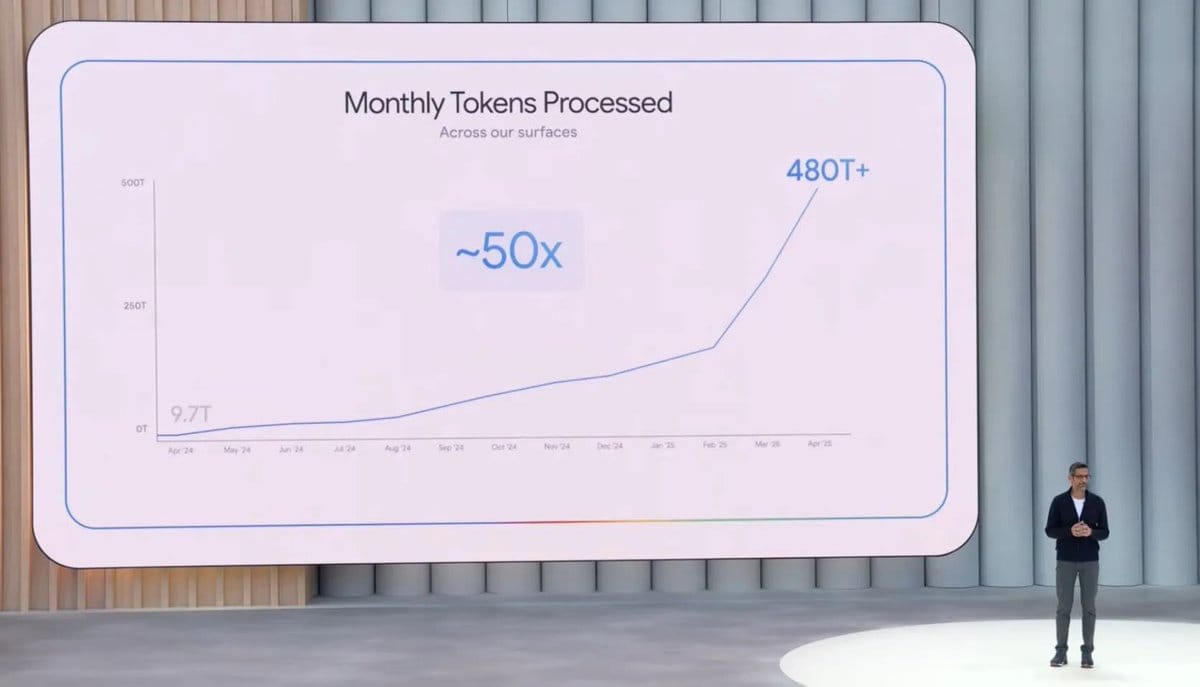
The only problem really is the price.
The Google AI Ultra package costs $250 USD/month…
Just another reminder that closed source models aren’t freely available to everyone, especially if there are no open source competitors. Frontier level AI must be open sourced, otherwise only those who can afford it will have the luxury of using the best AI models.
Dartmouth are using chatbots for mental health therapy
There's been a lot of talk recently about how AI is not just integrating into our working lives – providing coding support, helping us to synthesise information, and so on – but also into our personal lives. People are using ChatGPT, Claude, and other AI models to help them understand and process their feelings, treating it like a friend, or in many cases, a therapist.
The team at Dartmouth College's Geisel School of Medicine are drilling down on the potential benefits of using generative AI to deliver mental health therapy, and the results are pretty wild.
They found that participants who interacted with 'Therabot', which was built using Falcon and Llama, saw a 51% decrease in depression symptoms, 31% in anxiety symptoms, and 19% in eating disorder symptoms. Therabot was built and fine-tuned on tens of thousands of hours of manufactured therapist-patient dialogue.
Image source: The New York Times
So how did a chatbot achieve results comparable to traditional therapy?
The secret sauce seems to be in the relationship-building. Participants didn't just answer Therabot's prompts; they actively initiated conversations, treating it "almost like a friend". The bot was available 24/7, and usage spiked during vulnerable times like the middle of the night when traditional therapists wouldn't be available.
What's fascinating is that users reported a "therapeutic alliance”, a kind of trust and collaboration between patient and therapist, at levels comparable to in-person therapy. Over the 8-week trial, participants engaged with Therabot for an average of 6 hours total, equivalent to about 8 traditional therapy sessions.
The bot's approach is grounded in evidence-based practices from cognitive behavioural therapy, but with a twist: it personalises its responses based on what it learns during conversations (much like a human is supposed to).
If someone with anxiety says they're feeling overwhelmed, Therabot might respond with "Let's take a step back and ask why you feel that way", encouraging self-reflection.
The most striking finding?
75% of participants weren't receiving any other treatment.
This highlights the massive gap in mental health care. For every available provider in the US, there's an average of 1,600 patients with depression or anxiety alone. While Therabot isn't meant to replace human therapists (yet), it aims to help people who can’t necessarily afford traditional therapy in the moment.
Mind you, they used Falcon and Llama models, nowhere near the best AI models available. You can imagine then, how many people are using ChatGPT for therapy; the best models on the planet. The reality is, therapists just don’t have a very good reputation, and people are more than willing to use AI if they feel it will help them.
Note: “people are more than willing to use AI if they feel it will help them” - this doesn’t necessarily mean it will help them, it simply may seem that way is all.
You can read more about the study here [Link].
I want to keep bringing these AI updates to you, so if you’re enjoying them, it’d mean a lot to me if you became a premium subscriber.
As always, Thanks for reading ❤️.
Written by a human named Nofil
Reply